
What Is Scientific Data?
Scientific data refers to information collected through systematic observation, measurement, and experimentation as part of the scientific process. It serves as the foundation for generating knowledge, validating hypotheses, and building models across disciplines.
Scientific data can include:
- Raw sensor measurements (e.g., temperature, pressure, spectral data)
- Derived datasets (e.g., statistical summaries, processed images)
- Simulation outputs (e.g., from computational chemistry or climate models)
- Metadata (e.g., experimental conditions, instrument calibration)
- Provenance (e.g., who did what, when, and how)
Overview of the Scientific Process
- Observation
-
- Identifying phenomena or patterns in nature.
- Often leads to forming initial research questions.
- Hypothesis Formation
-
- Proposing explanations or predictions that are testable.
- Experimentation
-
- Designing experiments or simulations to test hypotheses.
- Collecting data through instruments, sensors, or computation.
- Analysis
-
- Processing, cleaning, and analyzing data using statistical or computational methods.
- Interpretation
-
- Drawing conclusions and validating results against hypotheses.
- Often leads to refinement of hypotheses or models.
- Publication & Sharing
-
- Communicating findings with supporting data and metadata for validation and reuse.
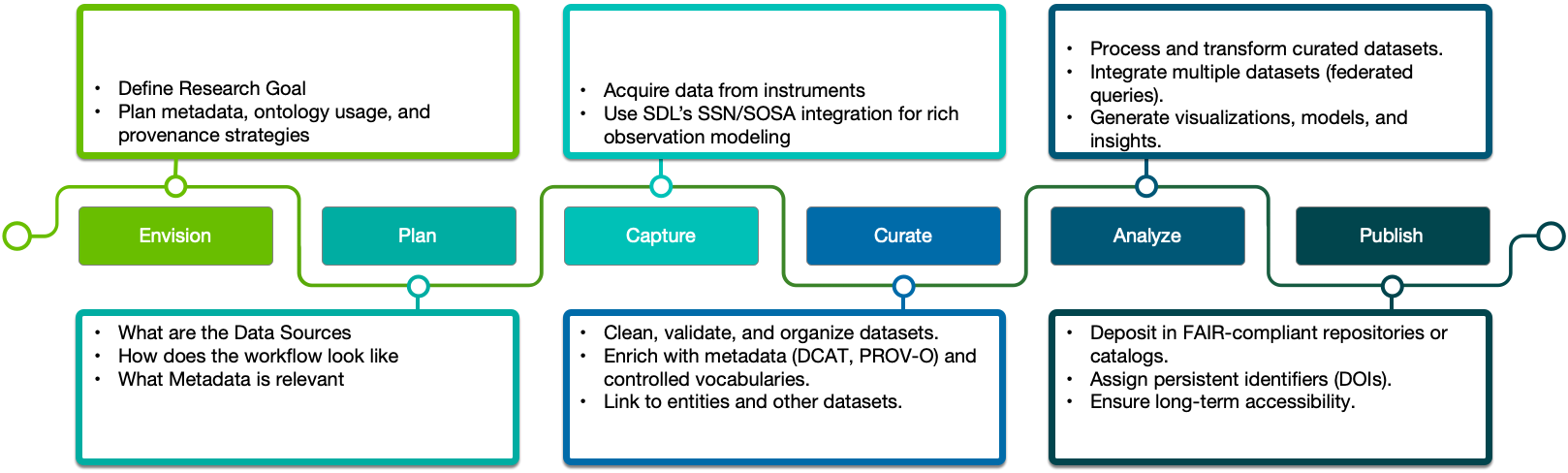
Stages of Scientific Data
Challenges in Managing Scientific Data
- Volume High-throughput instruments and simulations produce massive datasets. Storage and access become critical challenges.
- Variety Heterogeneous formats (CSV, NetCDF, HDF5, images, RDF, etc.). Domain-specific metadata standards and vocabularies.
- Complexity Multi-step workflows with complex dependencies and provenance chains. Need to track how data was generated and transformed.
- Reproducibility Difficult to reproduce results without detailed metadata, provenance, and code. Often requires linking data with computational environments.
- Interoperability Cross-disciplinary research needs data that is machine-readable and semantically integrated. Requires use of shared ontologies, controlled vocabularies, and Linked Data standards.
- Accessibility & FAIR Principles Data must be Findable, Accessible, Interoperable, and Reusable. Often neglected in legacy systems or informal data management practices.
- Preservation & Provenance Long-term preservation of data and its context (e.g., software versions, calibration files) is hard. Provenance tracking is often missing or incomplete.
Why Good Data Management Matters
Enables reproducibility and trust in scientific results. Supports interdisciplinary research and data reuse. Maximizes the return on investment for funded research. Accelerates discovery by making data searchable, accessible, and analyzable.